
PyTorch#
- 由 Facebook 人工智能研究小组开发的机器学习框架
- 代码简洁、符合人类思维、易上手
- 少量代码即可完成机器学习任务
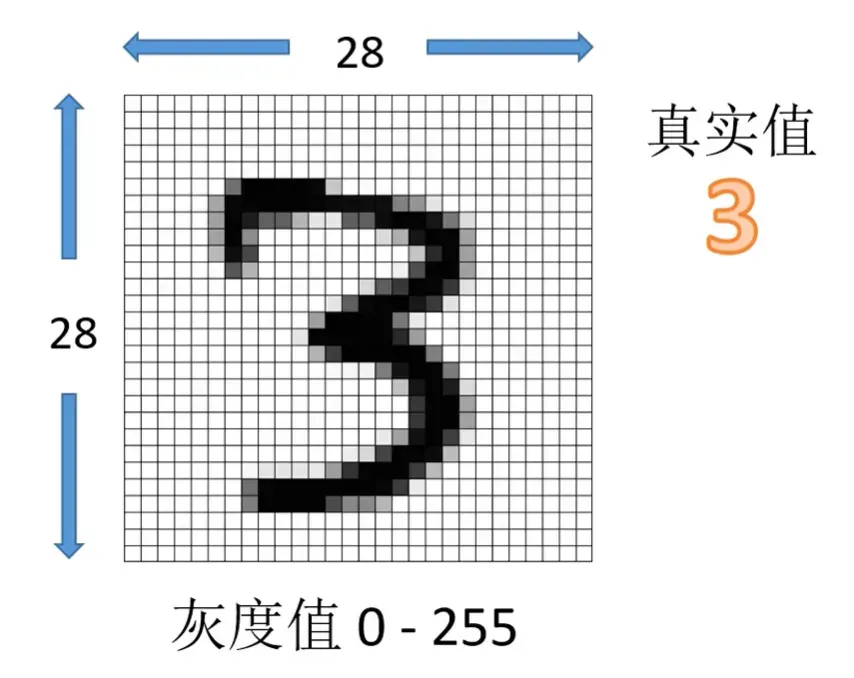
MNIST 数据集#
- 手写数字图片 7 万张
- 训练集 6 万张 + 测试集 1 万张
- 每张图片大小为 28*28 像素
- 灰度值范围 0-255
- 每张图片配有一个标记,既这张图片的真实值
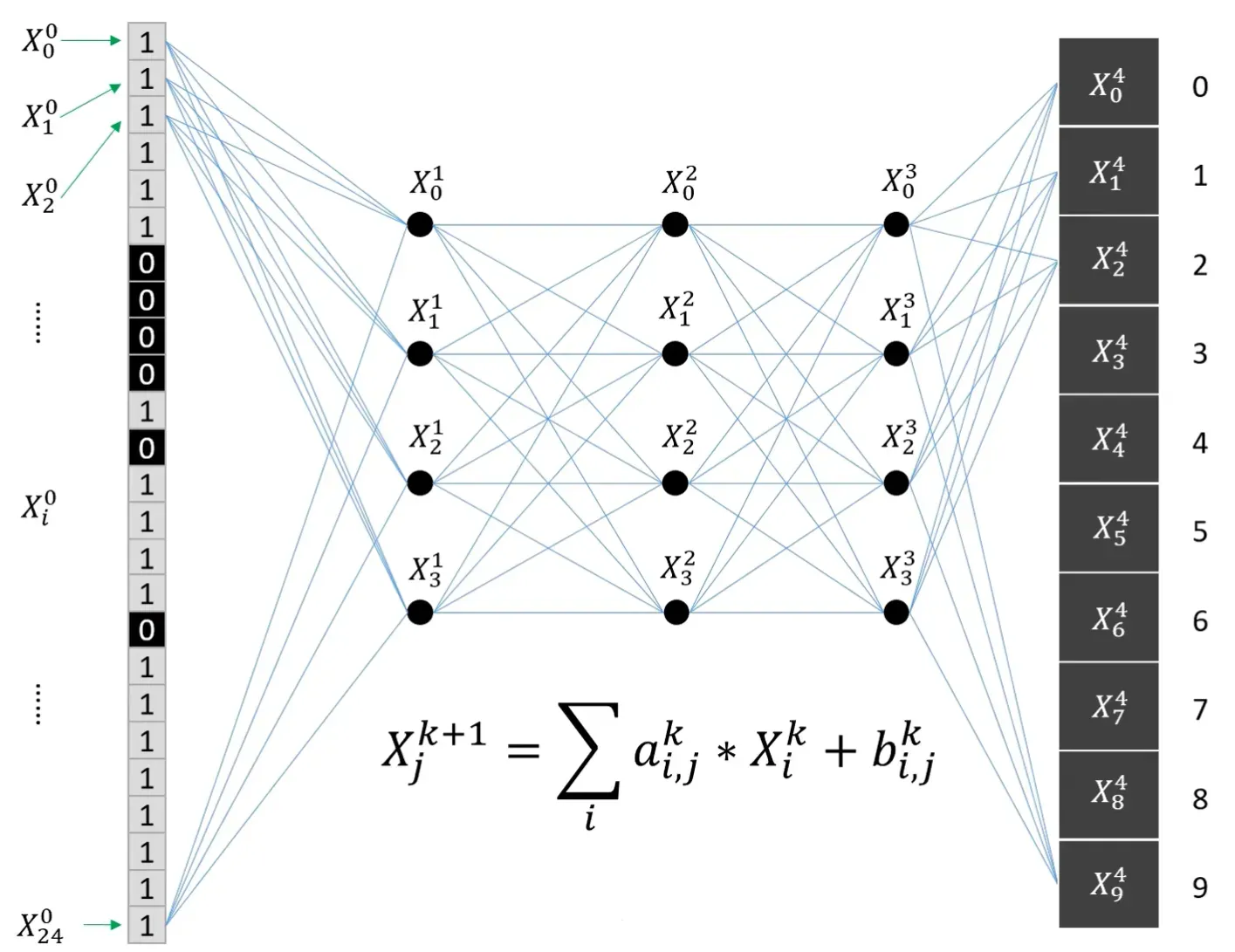
设计神经网络#
设有这样一张图片,大小为 5*5,内容为数字 7:

-
将像素重新排列成为一维阵列,构成神经网络的
第零层节点,设第0层节点中的数值为 X00、X10、X20、……、X240 -
计算
第一层节点的数值,例如 X01 = ∑ai,10 * Xi0 + bi,10字母
i表示前一层的节点序号 -
同理构建第二、三、四层节点,节点传播公式也扩展为Xk+11 = ∑ai,1k * Xik + bi,1k
字母
k和k+1表示网络层数 -
最后一层节点即为输出层,输出层有十个节点,每个节点对应 0-9 的数字,节点的数值就是该节点对应数字的概率,表示这张图片是某数字的概率
输出节点归一化#
由于节点传播公式中的 a、b 是任意的,所以输出层节点上的数值也应该是任意的,但概率的取值范围是 0-1,且十个概率加在一起应该等于 1。
所以将输出节点的数值进行如下处理:
- 用自然常数 e 对 X0、X1、X2、……、X9 进行一次指数运算,将变成每个数都变为正数,得到 eX0、eX1、X2、……、X9
- 将上一步得到的十个数字求和,得到 ∑eXi
- 用第二步中得到的数字作分母,用eX0、eX1、X2、……、X9 除以 ∑eXi
这样便得到了在 0-1 范围内,且总和为 1 的数组,以上便是 softmax 归一化。
训练#
上面的步骤得到了一组看上去像是概率的数字,但并不具备概率的意义,因为任意取值得到的 a、b 并不一定会使得到的数组接近真实概率,还需要经过训练才能让其具备识别的能力。
所以,可以把神经网络理解为一个函数。训练的过程,就是调整函数中的参数的过程。在这个例子里面,我们每次只用了一张图片来调整网络参数,也可以每次将几个图片打包为一个 batch,一起发给神经网络来调整参数。
上面的例子中,所有节点间的计算都是线性的,所以网络的总输入和总输出也是线性的。但对于很多问题,输入输出间存在非线性。所以我们会在在节点传播公式中套上一个非线性函数 f(),称为激活函数。常见的有对数函数、双曲函数、整流函数等等。
编写代码#
这段代码用到了 numpy、torch、torchvision、matplotlib 四个库,用下面的命令进行安装:
pip install numpy torch torchvision matplotlib下面是项目代码:
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
import matplotlib.pyplot as plt
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc1 = torch.nn.Linear(28*28, 64)
self.fc2 = torch.nn.Linear(64, 64)
self.fc3 = torch.nn.Linear(64, 64)
self.fc4 = torch.nn.Linear(64, 10)
def forward(self, x):
x = torch.nn.functional.relu(self.fc1(x))
x = torch.nn.functional.relu(self.fc2(x))
x = torch.nn.functional.relu(self.fc3(x))
x = torch.nn.functional.log_softmax(self.fc4(x), dim=1)
return x
def get_data_loader(is_train):
to_tensor = transforms.Compose([transforms.ToTensor()])
data_set = MNIST("", is_train, transform=to_tensor, download=True)
return DataLoader(data_set, batch_size=15, shuffle=True)
def evaluate(test_data, net):
n_correct = 0
n_total = 0
with torch.no_grad():
for (x, y) in test_data:
outputs = net.forward(x.view(-1, 28*28))
for i, output in enumerate(outputs):
if torch.argmax(output) == y[i]:
n_correct += 1
n_total += 1
return n_correct / n_total
def main():
train_data = get_data_loader(is_train=True)
test_data = get_data_loader(is_train=False)
net = Net()
print("initial accuracy:", evaluate(test_data, net))
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
for epoch in range(2):
for (x, y) in train_data:
net.zero_grad()
output = net.forward(x.view(-1, 28*28))
loss = torch.nn.functional.nll_loss(output, y)
loss.backward()
optimizer.step()
print("epoch", epoch, "accuracy:", evaluate(test_data, net))
for (n, (x, _)) in enumerate(test_data):
if n > 3:
break
predict = torch.argmax(net.forward(x[0].view(-1, 28*28)))
plt.figure(n)
plt.imshow(x[0].view(28, 28))
plt.title("prediction: " + str(int(predict)))
plt.show()
if __name__ == "__main__":
main()